Zu einem persönlichen Daten-GAU ist es bestimmt bei jedem schon einmal gekommen. In meinen frühen Jahren musste ich zweimal Datenverluste durch kaputte Festplatten verkraften. Danach folgten sporadische Kopien auf externe Festplatten, mal hier und mal dort ein Backup
. Eine unkoordinierte Sammlung an externen Festplatten, gebrannten CDs und DVDs entstand. Zehn Jahre später gab es erste Fehler beim Lesen gebrannter CDs, außerdem wusste ich auch nicht genau was sich wo genau befand. Seit 2015 betreibe ich nun einen kleinen Heimserver mit FreeNAS, den meine Rechner als Zielmedium für ihr automatisiertes Backup nutzen. Außerdem lagern dort meine restlichen Daten. Wenn eine Platte ausfällt ist noch alles im Lot dank des RaidZ2 aber was ist, wenn der Blitz einschlägt, das Haus brennt, jemand beschließt meinen kleinen Server einfach mitzunehmen oder ich einen unsinnigen Befehl auf der Kommandozeile eintippe? Richtig, dann ist alles weg.
Trotz, dass ich davor tatsächlich panische Angst habe und mir diese Unzulänglichkeit seit Inbetriebnahme der FreeNAS Box bewusst ist, fehlte es bisher an einem richtigen Backup. Warum? Weil der Weg zu einem richtigen Backup doch schon recht steinig ist, wenn man nur über Halbwissen verfügt.
Mittlerweile liegt eine Kopie meiner Daten ein paar Kilometer weit weg an einem vertrauensvollen Ort, ich schlafe ruhiger und mein Halbwissen zum Thema ZFS hat sich zumindest ein klein wenig erweitert. Vielleicht nützt dieses Wissen dem ein oder anderen etwas. Wenn nicht, so hab ich mit der folgenden Anleitung immernoch eine Notiz wie das Backup im Falle des Falles einzuspielen ist.
Anforderungen
Folgende Kriterien waren für mich entscheidend:
- offsite Backup – die Daten sollen an einem physisch anderen Ort aufbewahrt werden
- keine Cloud – ich möchte keinen (kommerziellen) Dritten dazwischen schalten; keine Terrabytes über das Internet morsen
- schneller Zugriff auf einzelne Dateien im Notfall ohne spezielle Hardware aufsetzen zu müssen
Folgende Kriterien sind für mich nicht entscheidend:
- 24/7 Aktualität des Backups – es geht hier nur um meine privaten Daten
- 24/7 Zugang zum Backup
Backup-Strategie
Es steht ja schon im Titel – es ist eine Lösung mit externer Festplatte geworden. Diese wird per USB an die FreeNAS Box angeschlossen, das Update-Skript gestartet und anschließend wird die Platte an einen vertrauensvollen Ort transferiert.
Das Ganze findet im rotierenden System statt. Wenn also eine Platte zum vertrauenvollen Ort wandert, wird gleichzeitig eine von dort wieder mitgenommen und wiederum mit dem aktuellen Datenstand versehen. Der Plan ist dies monatlich durchzuführen.
Da die Daten auf der FreeNAS Box schon in einem ZSF Pool liegen bietet es sich natürlich an diesen mit zfs send | zsf receive auf die USB-Platte zu spiegeln. Für alle Eventualitäten hebe ich noch die letzen 3 Snapshots auf.
Umsetzung
1. Pool anlegen
Auf der USB-Platte muss natürlich erstmal ein ZSF Pool angelegt werden. Die Platte wird dazu an das FreeNAS angeschlossen und anschließend in der Konsole ein dmesg ausgeführt. Die letzten Zeilen der dmesg Ausgabe könnten zum Beispiel so aussehen:
umass1 on uhub2
umass1: <Western Digital Elements 25A2, class 0/0, rev 2.10/10.14, addr 5> on usbus0
umass1: SCSI over Bulk-Only; quirks = 0xc101
umass1:8:1: Attached to scbus8
da1 at umass-sim1 bus 1 scbus8 target 0 lun 0
da1: <WD Elements 25A2 1014> Fixed Direct Access SPC-4 SCSI device
da1: Serial Number 575842314141364832304143
da1: 40.000MB/s transfers
da1: 1907697MB (3906963456 512 byte sectors)
da1: quirks=0x2<NO_6_BYTE>Code-Sprache: Bash (bash)Das da1 ist die gesuchte Information (USB-Speicher werden in FreeBSD mit da0, da1, da1, … bezeichnet), die Platte können wir nun nämlich über /dev/da1 ansprechen. Mit dem folgenden Befehl wird die ganze Platte für den ZFS Pool verwendet, wir nennen ihn backup.
Achtung: Seid euch bitte 100% sicher, dass /dev/da1 eure USB-Platte anspricht und keine andere, sonst braucht ihr kein Backup mehr 😉
zpool create -f -O compression=lz4 -O atime=off -O casesensitivity=insensitive -O normalization=formD backup /dev/da1Code-Sprache: Bash (bash)Wenn keine Fehlermeldung aufgetaucht ist können wir nun den Pool auswerfen
, unser Backup-Script wird ihn später wieder einbinden.
zpool export backupCode-Sprache: Bash (bash)2. Backup Skript
Meine Daten liegen alle in dem Pool data. Darin habe ich mehrere Datasets, wovon im folgenden Beispiel nur media und timemachine in das Backup sollen.
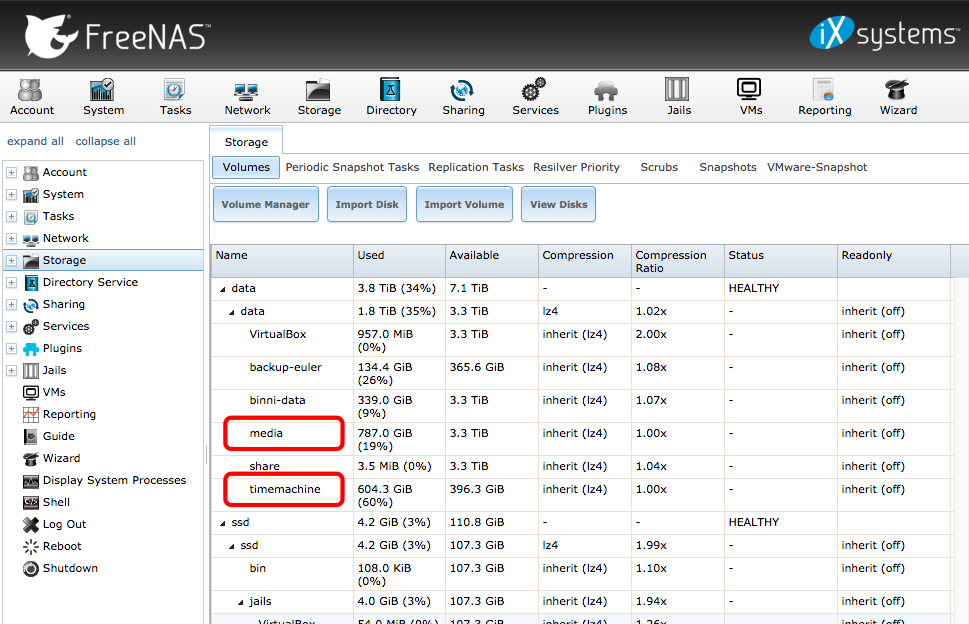
Das folgende Skript wird zum Beispiel als backup.sh in einem Verzeichnis auf dem FreeNAS gespeichert. Im oberen Bereich erfolgen die individuellen Anpassungen (siehe Kommentare im Skript).
#!/bin/bash
# Pool mit den zu sichernden Daten
MASTERPOOL="data"
# Backup-Pool
BACKUPPOOL="backup"
# Datasets, die in das Backup sollen
DATASETS=("media" "timemachine")
# Anzahl der zu behaltenden letzten Snapshots, mindestens 1
KEEPOLD=3
# Praefix fuer Snapshot-Namen
PREFIX="auto"
# -------------- ab hier nichts aendern ---------------
zpool import $BACKUPPOOL
KEEPOLD=$1
for DATASET in ${DATASETS[@]}
do
# Namen des aktuellsten Snapshots aus dem Backup holen
recentBSnap=$(zfs list -rt snap -H -o name "${BACKUPPOOL}/${DATASET}" | grep "@${PREFIX}-" | tail -1 | cut -d@ -f2)
if [ -z "$recentBSnap" ]
then
dialog --title "Kein Snapshot gefunden" --yesno "Es existiert kein Backup-Snapshot in ${BACKUPPOOL}/${DATASET}. Soll ein neues Backup angelegt werden? (Vorhandene Daten in ${BACKUPPOOL}/${DATASET} werden ueberschrieben.)" 15 60
ANTWORT=${?}
if [ "$ANTWORT" -eq "0" ]
then
# Backup initialisieren
NEWSNAP="${MASTERPOOL}/${DATASET}@${PREFIX}-$(date '+%Y%m%d-%H%M%S')"
zfs snapshot -r $NEWSNAP
zfs send -v $NEWSNAP | zfs recv -F "${BACKUPPOOL}/${DATASET}"
fi
continue
fi
# Check ob der korrespondierende Snapshot im Master-Pool existiert
origBSnap=$(zfs list -rt snap -H -o name "${MASTERPOOL}/${DATASET}" | grep $recentBSnap | cut -d@ -f2)
if [ "$recentBSnap" != "$origBSnap" ]
then
echo "Fehler: Zum letzten Backup-Spanshot ${recentBSnap} existiert im Master-Pool kein zugehoeriger Snapshot."
continue
fi
echo "aktuellster Snapshot im Backup: ${BACKUPPOOL}/${DATASET}@${recentBSnap}"
# Name fuer neuen Snapshot
NEWSNAP="${MASTERPOOL}/${DATASET}@${PREFIX}-$(date '+%Y%m%d-%H%M%S')"
# neuen Snapshot anlegen
zfs snapshot -r $NEWSNAP
echo "neuen Snapshot angelegt: ${NEWSNAP}"
# neuen Snapshot senden
zfs send -v -i $recentBSnap $NEWSNAP | zfs recv "${BACKUPPOOL}/${DATASET}"
# alte Snapshots loeschen
zfs list -rt snap -H -o name "${BACKUPPOOL}/${DATASET}" | grep "@${PREFIX}-" | tail -r | tail +$KEEPOLD | xargs -n 1 zfs destroy -r
zfs list -rt snap -H -o name "${MASTERPOOL}/${DATASET}" | grep "@${PREFIX}-" | tail -r | tail +$KEEPOLD | xargs -n 1 zfs destroy -r
done
zpool export $BACKUPPOOL
Code-Sprache: Bash (bash)3. Backup durchführen
So ein Backup auf eine USB-Platte kann schon ein ganzes Weilchen dauern. Damit die Skript-Ausführung nicht abbricht falls zum Beispiel die Terminal-App aus Versehen geschloßen wird oder die SSH-Verbindung zu FreeNAS Schluckauf bekommt sollte das ganze in einer virtuellen Konsole ausgeführt werden. Dazu eignet sich zum Beispiel das Programm tmux. Dieses wird auf der Konsole einfach mit dem Befehl tmux gestartet und es öffnet sich eine virtuellen Konsole. Um diese zu verlassen ohne sie zu schließen wird einfach [Strg]+[B] und anschließend [D] gedrückt (auch wenn gerade das Backu-Skript läuft). Zum Zurückkehren wird der Befehl tmux attach genutzt (Achtung: Wenn ihr als root tmux startet, müsst ihr natürlich wieder als root die virtuelle Sitzung aufnehmen).
Es wird in der virtuellen Konsole mit cd in das Verzeichnis mit dem Backup Script gewechselt und anschließend das Skript gestartet:
./backup.shCode-Sprache: Bash (bash)Was passiert jetzt? Zunächst wird der backup Pool eingebunden. Anschließend wird das eigentliche Backup durchgeführt. Dabei erscheint beim erstmaligen Durchlauf für jedes Dataset ein Dialog, welcher fragt ob ein neues Backup angelegt werden soll. Hier ist natürlich ja auszuwählen. Solltet dieser Dialog irgendwann später nochmal auftauchen so ist etwas schief gegangen.
Das Skript erzeugt nun automatisch mit jedem Durchlauf einen Snapshot für jedes angegebene Dataset und benennt diesen mit dem aktuellen Datum, zum Beispiel: data/timemachine@auto-20180218-232209. Dieser Snapshot wird anschließend inkrementell auf die USB-Platte gesendet. Beim ersten Durchgang dauert dies je nach Größe der Daten recht lange. Bei weiteren Durchläufen werden nur noch die Änderungen übertragen. Anschließend werden sowohl auf dem FreeNAS als auch auf der USB-Platte alte Snapshots gelöscht, bis auf die drei letzten (kann mit KEEPOLD eingestellt werden).
Zum Abschluss exportiert das Skript noch den backup Pool – die USB-Platte wird ausgeworfen
. Wenn keine Fehlermeldungen aufgetaucht sind kann die Platte nun wieder abgestöpselt werden.
4. Backup einspielen
Nehmen wir an der Nachbar über mir hat einen Wasserschaden und mein FreeNAS ist baden gegangen. Was nun? Wie komme ich wieder an meine Daten? Dieser Schritt sollte unbedingt getestet werden, bevor man sich zufrieden zurücklehnt und in Sicherheit wägt.
4.1 Komplettes Backup in einen neuen Pool einspielen
Für diesen Fall muss selbstverständlich ein Rechner mit einem ZFS unterstützenden Betriebssystem bereit stehen. Wir gehen einfach mal wieder von einer FreeNAS Box aus. Auf diesem Rechner wird ein neuer Pool angelegt (z.B. in der FreeNAS Weboberfläche) mit dem Namen newpool. Anschließend wird die USB-Platte mit dem Backup angeschlossen und eingebunden.
zpool import backupCode-Sprache: Bash (bash)Mit dem obigen Skript haben wir nur einzelne Datasets gesichert, diese müssen jetzt auch einzeln wiederhergestellt werden. Zunächst schauen wir, was denn eigentlich da ist.
zfs list -rt snap -o name,creation backupCode-Sprache: Bash (bash)Dieser Befehl erzeugt eine Ausgabe wie zum Beispiel:
NAME CREATION
backup/media@auto-20180219-124435 Mon Feb 19 12:44 2018
backup/media@auto-20180219-130558 Mon Feb 19 13:05 2018
backup/timemachine@auto-20180219-124435 Mon Feb 19 12:44 2018
backup/timemachine@auto-20180219-130558 Mon Feb 19 13:05 2018Code-Sprache: Bash (bash)Um nun den letzten Snapshot vom Dataset media einzuspielen ist folgendes notwendig:
zfs send -R backup/media@auto-20180219-130558 | zfs recv -vF newpool/mediaCode-Sprache: Bash (bash)Jetzt sollten die eingespielten Daten noch geprüft werden:
zpool scrub newpoolCode-Sprache: Bash (bash)Zum Schluss wird die USB-Platte ausgehangen:
zpool export backupCode-Sprache: Bash (bash)4.2 Wie komme ich ganz schnell an DIE eine Datei?
Im Falle des Daten-GAUs ist möglicherweise kein Gerät vorhanden, um die ganzen Datasets wieder einzuspielen, trotzdem muss man unter Umständen an bestimmte Daten herankommen. Da mit zfs send | zfs receive ein vollständiges Dateisystem auf die USB-Platte geschrieben wurde, kann diese auch an jedem ZFS unterstützenden Rechner gelesen werden.
Ich habe das Ganze einmal an meinem Mac ausprobiert. Dazu muss auf dem Mac OpenZFS on OSX installiert werden. Nun kann die USB-Platte an den Mac angeschlossen werden. Etwaige Angebote von OSX die Platte zu initialisieren oder ähnliches sind strengstens abzulehnen.
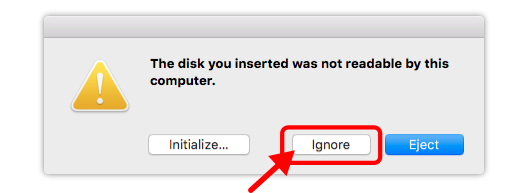
Der backup Pool auf der USB-Platte wird nun als readonly nach /Volumes/backup gemountet. Da hierfür root Rechte notwendig sind, wird sudo benutzt, es verlangt anschließend das Nutzer-Passwort.
sudo zpool import -o readonly=on -o altroot=/Volumes/backup backupCode-Sprache: Bash (bash)Nun sollten die Datasets nach einige Sekunden im Finder auftauchen, Dateien können jetzt einfach auf den Mac kopiert werden. Zum Abschluss muss der Pool jedoch unbedingt wieder mit zpool export ausgeworfen werden.
zpool export backupCode-Sprache: Bash (bash)Anmerkungen
Wie bereits eingehend erwähnt: Die vorgestellte Backup Lösung ist meine eigene Variante für meine privaten Daten, von deren Existenz nicht das Weltgeschehen abhängt. Wenn ihr ähnliches vor habt, nutzt diese Anleitung als Hilfestellung aber informiert euch vorher ausführlich über ZFS, zum Beispiel dort:
Lest euch das obige Backup-Skript durch und versucht es nachzuvollziehen – nutzt es nicht blind, schreibt vielleicht sogar euer eigenes! Lest euch auf der Konsole eingegebene Befehle nocheinmal genau durch, bevor ihr auf Enter drückt. Testet euer Backup erstmal mit Testdaten. Probiert auch unbedingt Schritt 4 aus. Überprüft, welche Snapshots erstellt werden, zum Beispiel mit:
zfs list -rt snap -o name,creationCode-Sprache: TeX (tex)Ich wünsche euch viel Erfolg auf dem Weg zu eurem Backup!
- $KEEPOLD + 1[↩]
Schreibe einen Kommentar